今年的云服务商真是事故不断。6月12日是 GCP,10月20日是 AWS,这回轮到了 Cloudflare 。本来我是不知道前两个事故的,当时可能没在上(国际)网,但这次的事故我确实是亲身经历了。以下时间若无特殊说明,均为中国标准时间(UTC+8)。
事件经历
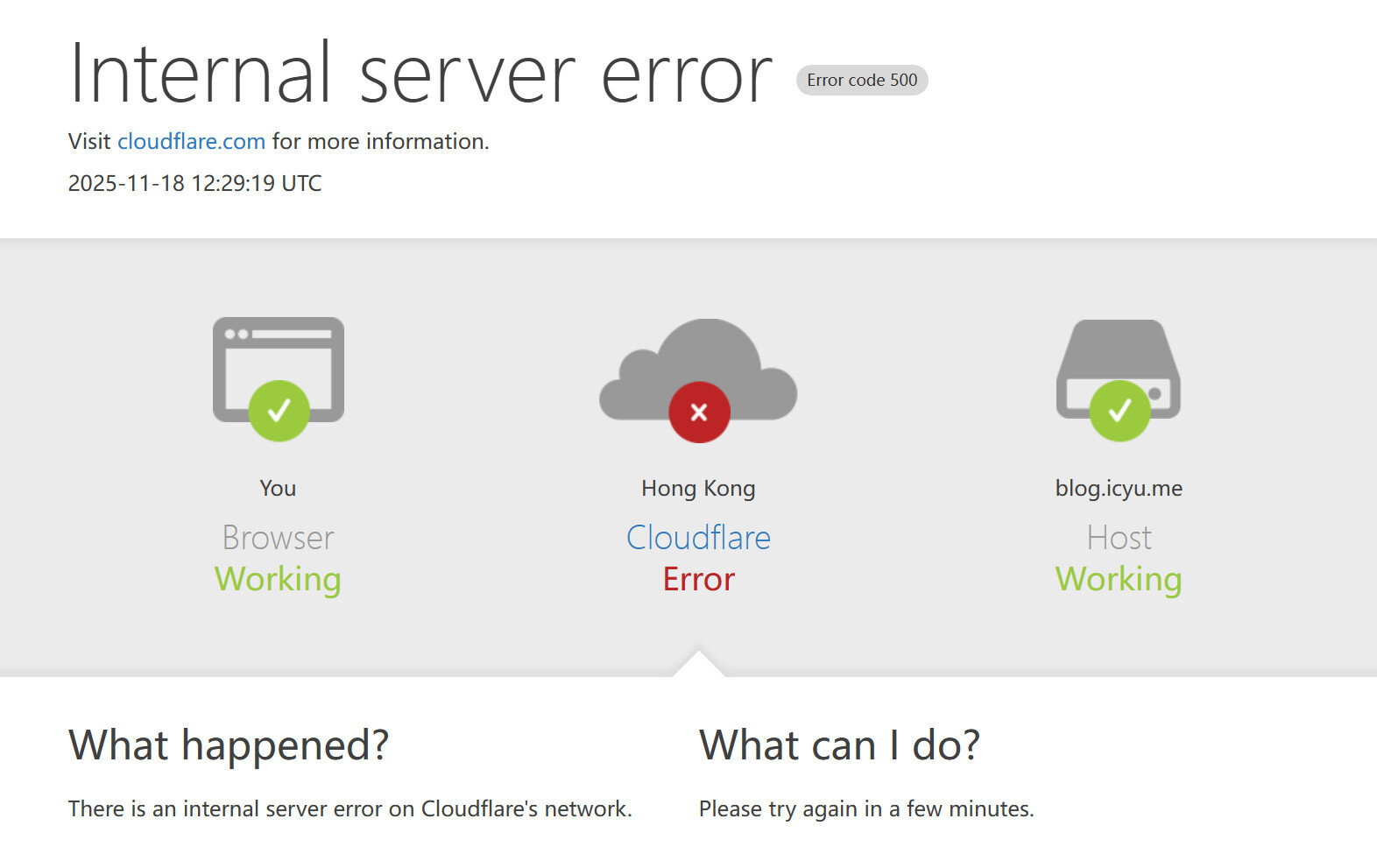
事件发生于晚上 19:30 左右。当时我正在查资料,发现 ScienceDirect 的人机验证(由 Cloudflare 提供)始终过不去。Cloudflare 的人机验证,以往都是简单点一下就通过了,不像 reCAPTCHA 那样经常要和拼图斗智斗勇;但今天我注意到只是显示红色的叉与失败提示。当然,我首先怀疑的是自己的网络环境问题,我尝试了更换其他来源的代理服务、重启相关软件、更换网络环境、更换设备,但仍然无法恢复。但我也没注意这个,毕竟上网遇到的疑难杂症可太多了。但之后,我访问 doi.org 的时候发现无法跳转,通过调试我发现网站竟然报了 500 错误。我在想,DOI 竟然故障了,这可是很严重的。但事情并没有那么简单。
接着可能是出于直觉,我访问了 Cloudflare Dashboard,发现页面空白,下面只有红色横幅提示鉴权失败;我搜索 Cloudflare 相关话题,看到搜索指数骤增以及社交媒体上瞬间炸锅,确认了这一点——这次是 Cloudflare,全球最大的 CDN 提供商(之一),出现了大规模的故障。很快,Cloudflare Status 上出现了醒目的通告,宣告了此次事件,此时是 19:48。这可谓是史无前例,本着看热闹不嫌事大的心理,我当即决定停下手头的工作 ~~(实则为找借口偷懒) ~~ 持续关注此次故障的最新动态。

事故波及到所有使用 Cloudflare CDN 的网站,包括 X、ChatGPT、Claude、Canva、AO3 等。当时我通过全球各地区的节点测试了一下,一开始有些地区的节点能够正常访问,但之后全都下线了。有的网站虽遭到牵连但可能是由于及时更改解析很快恢复正常了,例如 Facebook。此外,据称某些仅使用静态服务托管的网站没有问题。
Cloudflare 故障了,我的博客主站也无法幸免。尽管后端 Web 服务运作完全正常,我目前仍然坚持使用动态博客,博客程序包括图床、评论等功能完全独立于 Cloudflare。然而我无法着手恢复访问,因为域名解析到 Cloudflare 的网络,然而想更改解析就得访问 Cloudflare 的控制台,后者也下线了;还有一个办法是在域名注册商更改 nameserver,直接架空 Cloudflare。我觉得没必要这么干,因为很麻烦,况且只是个人博客也没必要,那些大网站还没恢复呢。不过我还是试图访问了一下我的域名注册商 Dynadot 的网站,结果它也因为使用了 Cloudflare 的 CDN 无法访问,这未免太黑色幽默了。对于个人用户来说,只能这样等待了。我自行部署的服务中,只有博客主站由于强依赖 443 端口因此用 Cloudflare 反代,其他服务部署在高位端口上,因此未受牵连。不过,如果 Cloudflare 的 DNS 解析也一并故障,那恐怕就麻烦了。
大约三个小时之后,到 22:30 左右,全球服务逐渐恢复正常。
历次事故回顾
今年很多知名云服务商都因为各种各样的小问题酿成了严重事故。6月12日,Google Cloud Service(GCP)推送的一个有问题的新特性影响了很多使用 GCP 的产品;10月20日,AWS 由于内部 DNS 解析失败导致大量服务不可用。
Cloudflare 曾在8月因机房意外停电且后备电源异常而中断了控制台访问长达40小时,不过好在只是影响控制没有影响已部署的网站访问。之前一次影响全球节点访问的事故还要追溯到2019年,当时是因为有问题的正则表达式执行时耗尽了全球节点的计算资源而宕机。
- GCP
- AWS
- Cloudflare
- Cloudflare Outage History (2019-2025)
- 关于 2019 年 7 月 2 日 Cloudflare 中断的详情(Cloudflare 官方)
- Cloudflare 控制平面和分析服务中断的事后分析(Cloudflare 官方)
- Cloudflare incident on August 21, 2025(Cloudflare 官方)
- CloudFlare中断超过40个小时 机房夜班竟然只有1名上班1周的新人 – 蓝点网
后续分析与原因
本次事故持续了近三个小时,相比之下即使是2019年的那次也仅持续了24分钟。在这么长的时间内都无法修复且波及全球,对于一个重要性如同基础设施一般的互联网服务提供商来说,确实是非常严重的。
事故结束后,Cloudflare 官方很快在博客中详细说明了本次事件的经过并披露背后原因。Cloudflare 承认,这是一次前所未有的严重事故。他们一开始怀疑这是一场空前的攻击,因为这次故障有一些异常表现:故障是间歇性的,从来没有内部故障会这样;Cloudflare Status 也遇到了问题,然而这是独立于Cloudflare的基础设施部署在 Amazon Cloudfront 上的。事后证明,前者是内部问题,而后者只是一个巧合。
我大致浏览了一下事故原因,其实说是低级错误也不为过。罪魁祸首是 Cloudflare 核心代理中的机器人管理模块(Bot Management),它的作用是判断访问用户是否是真人。具体而言,它从 ClickHouse 数据库中查询访问用户的特征,将其输入一个模型,然后可以得到一个分数,供客户进行过滤。然而,在数据库查询中没有指定表名也没有去重,在事故前的一次权限更新导致可访问的表变多,查询结果变为原来的两倍;同时,出于性能考虑,他们为该功能模块预分配了内存,使得其刚好能容纳原先的查询结果,因此当接收到比预期大两倍的查询时将会出错。然而在 Rust 代码中,他们使用了.unwrap()忽略错误直接试图读取结果,在返回结果成功时程序正常运行,但当返回结果中包含错误时,程序并不会妥善处理错误,而是直接异常退出,于是这导致了整个系统的崩溃。
- 官方博客分析:Cloudflare outage on November 18, 2025
- 官方社交媒体动态:Cloudflare on X: "On November 18 Cloudflare experienced a service outage, triggered by an issue with a Bot Management feature, impacting multiple Cloudflare services. Here's a detailed breakdown of what happened. https://t.co/7WArlr5ghI" / X
- 2025年11月18日 Cloudflare 大规模中断事件 - 知乎
- Cloudflare outage on November 18, 2025 post mortem | Hacker News
反思
对于开发者,应当妥善处理错误,尤其是在重要的生产代码中,不要写不负责任的代码。这与 Rust 的设计无关:即使是以显式错误处理闻名甚至臭名昭著的 Go,也可以有 panic(err) 的写法。我们应当认为所有可能抛出错误的地方都会在某个时候报错,即使不处理每个错误,至少也应当将其抛回统一处置,而不是自作主张地将达摩克利斯之剑悬于整个程序之上,除非是位于核心功能中,出错时确实有终止整个程序的必要。
对于运维人员,不应认为将服务部署在云上就能高枕无忧了,今年各个云服务商的事故让我们看到了这一点。但好像除了不用之外也没什么办法,尤其是 Cloudflare,因为一旦故障就没法做什么操作了。
对于个人,应当有一套自己的基础设施,不要强依赖于云服务,至少要有自己的一套后备方案。此外,也应看到我们如今对生成式 AI 的依赖。ChatGPT 和 Claude 均不可用,影响了很多人的工作。我们也许可以给自己设置一个“无 AI 日”来避免对这些 AI 服务的过度依赖,保持独立解决问题的能力。
本文因亲身经历了这次事件有感而发,仓促写就。本人并非这方面的专业人士,仅为业余爱好者,若有任何问题,请批评指正。转载请注明出处。全文无 AIGC。